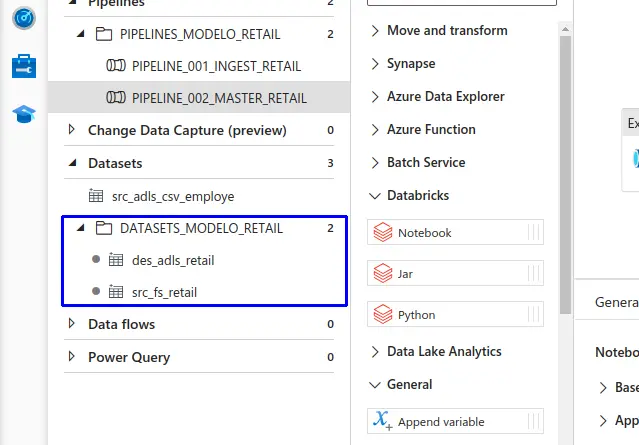
Pipelines - Azure Data Factory
Orquestación de Pipeline Ingest - Proyecto¶
Configuración del Origen¶
Para poder realizar este segmento del proceso es necesario tener los recursos como la Virtual Machine con su respectiva conexión de Integration Runtimes(IR), el recursos Azure Data Lake Storage Gen2
El Pipeline consiste en la ingesta de datos desde el recurso de Virtual Machine hacia el recurso Azure Data Lake Storage Gen2
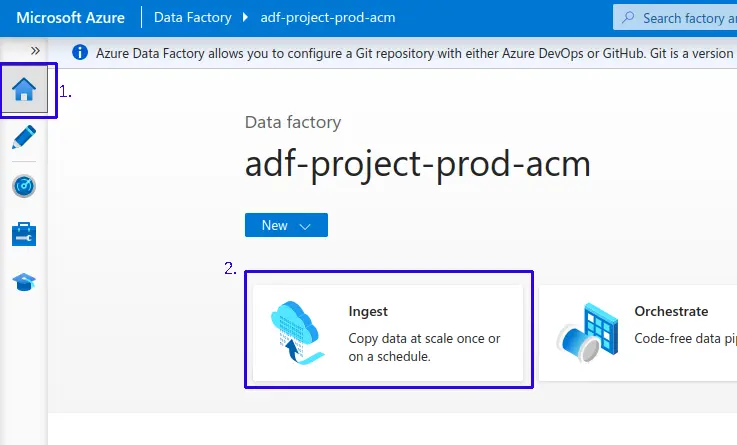
- 1.- Ingresamos a la sección de “Home” de Azure Data Factory
- 2.- Luego dar clic en “Ingest”
Configurar modo de ejecución:
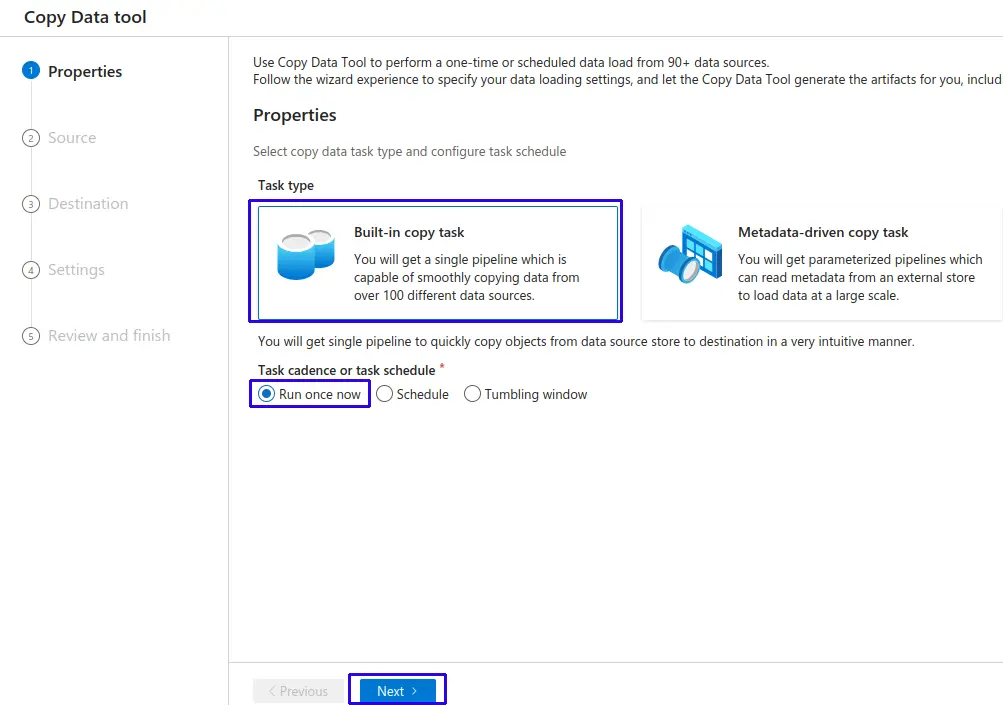
- Indicamos que vamos a realizar un tarea de tipo "Built-in copy task"
- Task cadence or task schedule: Seleccionamos "Run once now" que viene por defecto.
- Haz clic al botón "Next".
Configurar fuente de datos (Dataset):
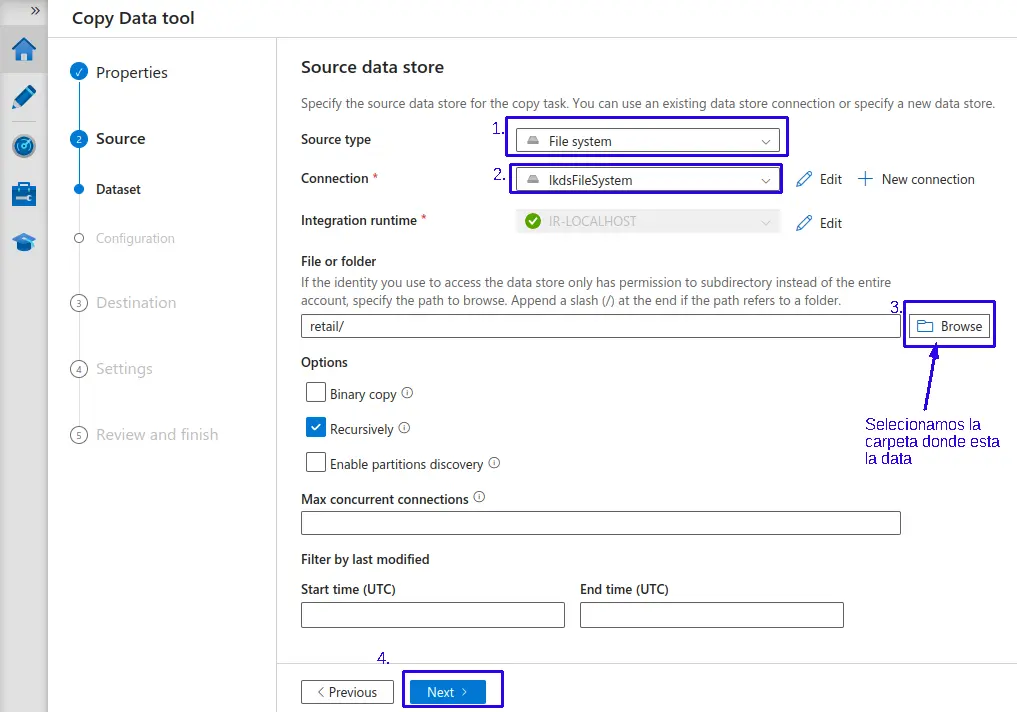
- 1.- En tipo de fuente (
Source type): Seleccionamos en este caso "File system", nos filtrara los linked services de "file system" para la conexión. - 2.- En conexión (
connection): Seleccionamos el linked service respectivo para este ejemplo el llamado "lkdsFileSystem".En este punto 2 nuestro Azure Data Factory ya está lleyendo nuestro entorno de la VM, que tambieé podría se un entorno On-Premise.
- 3.- Seleccionamos la carpeta donde se encuentra almacenada la data a trabajar.
- Mantenemos configuraciones por defecto.
- 4.- Haz clic en el botón "Next >".
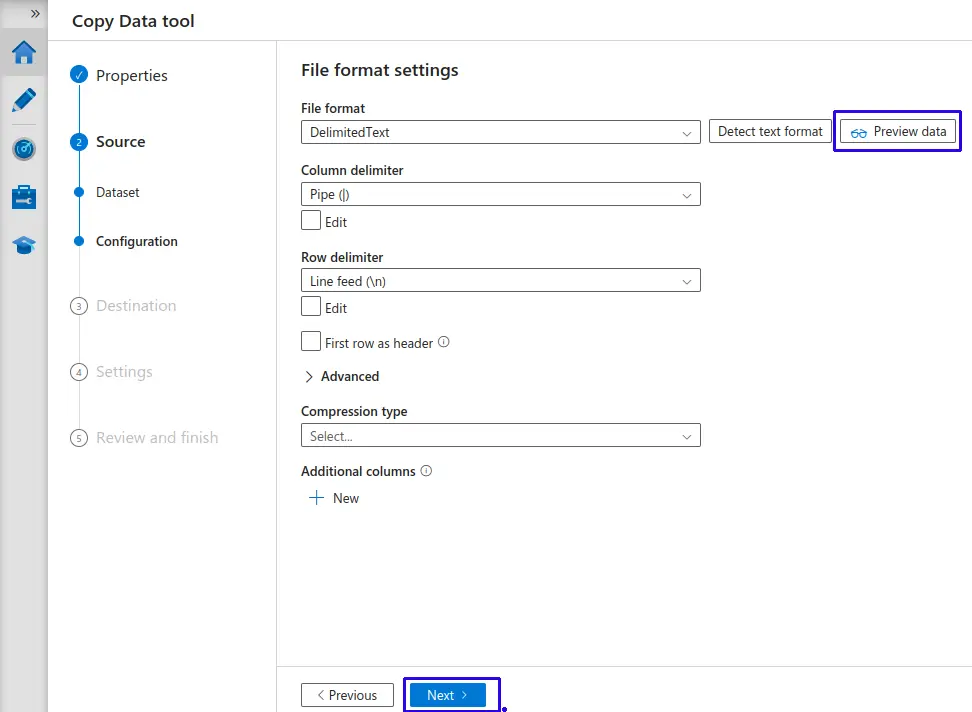
Configurar tipo de archivo (Configuration):
- Se identifica el formato de la data.
- Podemos pre visualizar la información obtenida para validar la data.
- Haz clic en el botón "Next >".
Configuración del Destino¶
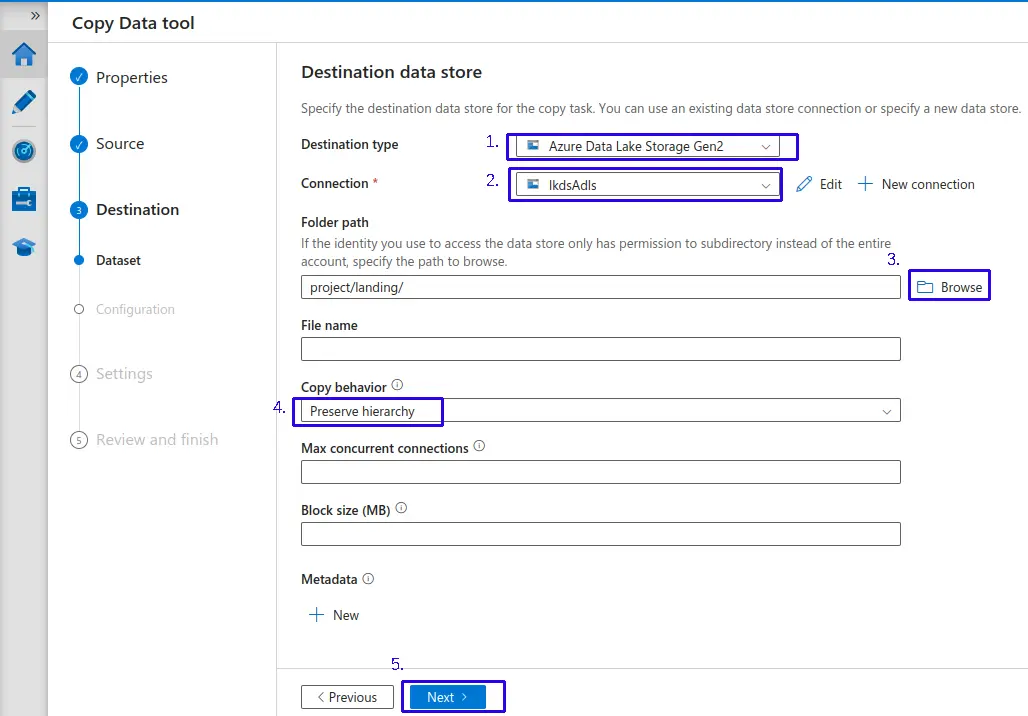
Configurar fuente de datos (Dataset):
- 1.- En tipo de fuente (
Source type): Seleccionamos en este caso "Azure Data Lake Storage Gen2", nos filtrara los linked services de "Azure Data Lake Storage Gen2" para la conexión. - 2.- En conexión (
connection): Seleccionamos el linked service respectivo para este ejemplo el llamado "lkdsAdls". - 3.- Seleccionamos el directorio donde se almacenaremos la data a ingestada.
- Mantenemos configuraciones por defecto.
- 4.- Seleccionamos como Comportamiento de copia(
Copy behavior): "Preserve hierarchy" Preservar la jerarquía - 5.- Haz clic en el botón "Next >".
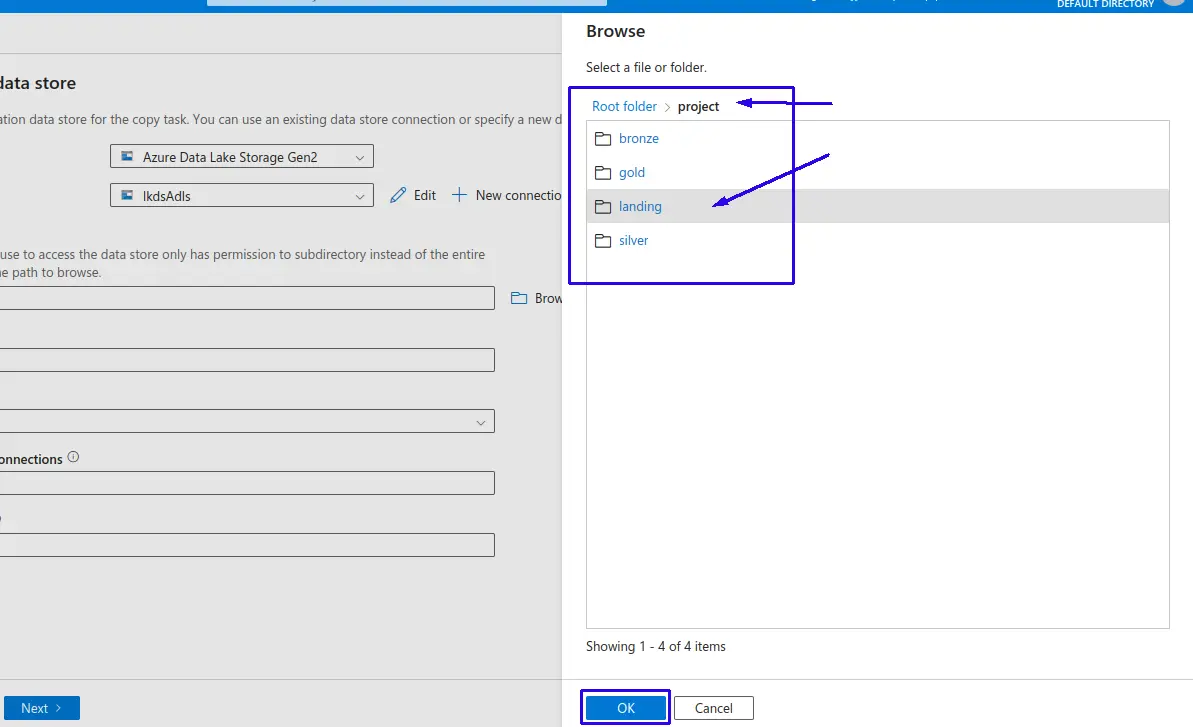
Acote punto 3 - Aki podemos ver la distribucion de directorios de nuestro container en Azure Data Lake Storage, en este caso seleccionaremos la capa "landing" donde almacenara la data cruda para poder ser procesada prosteriormente.
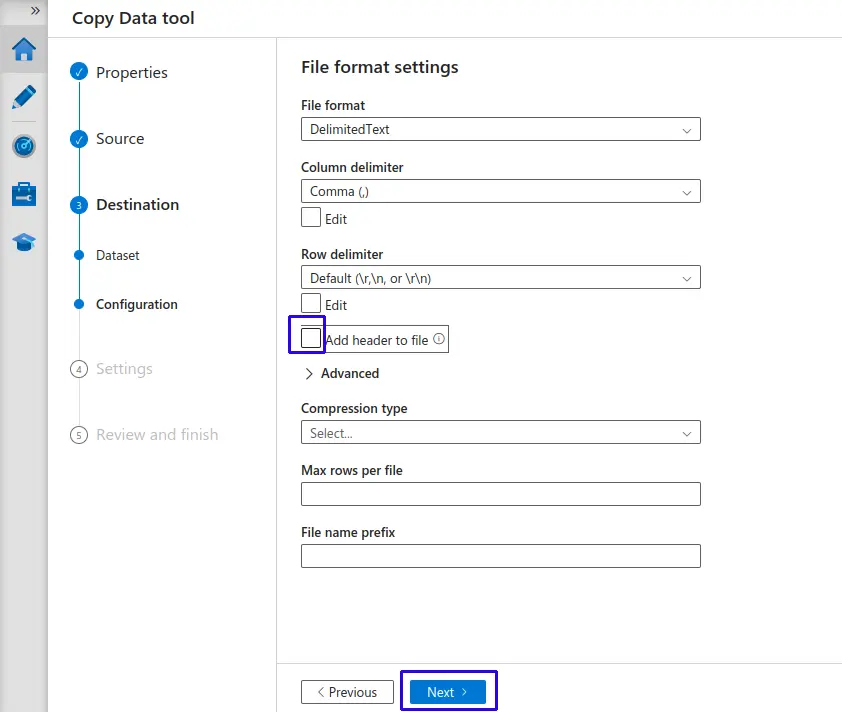
Configurar formato de archivo:
- Desactivamos la opción de Agregar encabezado al archivo (
Add header to file), en caso nuestros archivos no tengan un encabezado del origen - Haz clic en el botón "Next >".
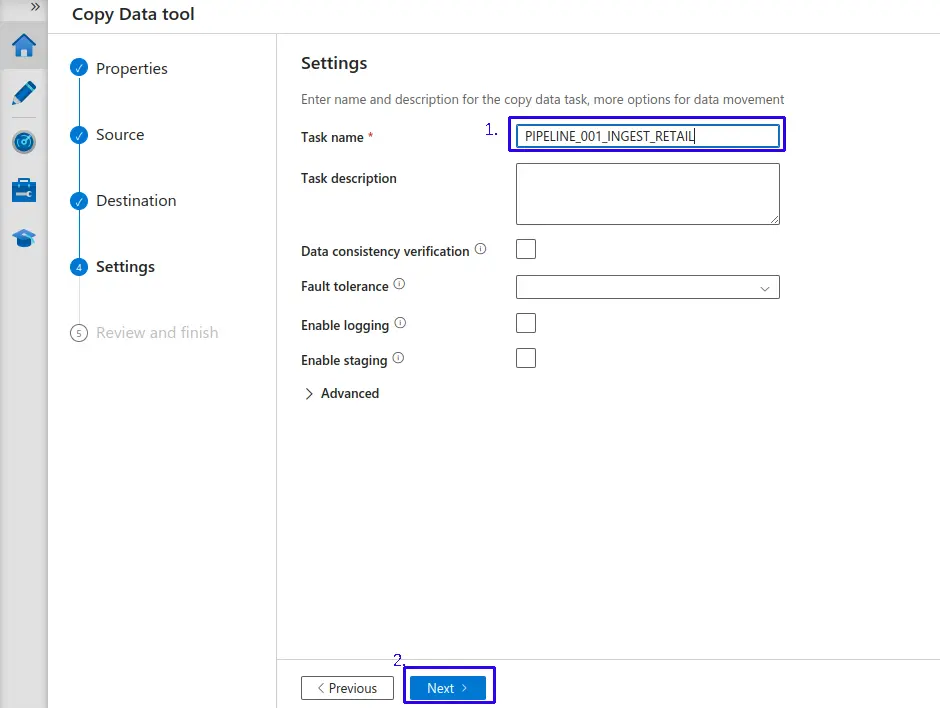
Configurar nombre de pipeline:
- 1.- Definimos un nombre para nuestro Pipeline, en este caso le asignaremos el nombre de "
PIPELINE_001_INGEST_RETAIL". - 2.- Haz clic en el botón "Next >".
Continuamos revisando las configuraciones y actualizamos los nombres de nuestros datasets para poder obtener una mejor identificación de los recursos a utilizar en este pipeline:
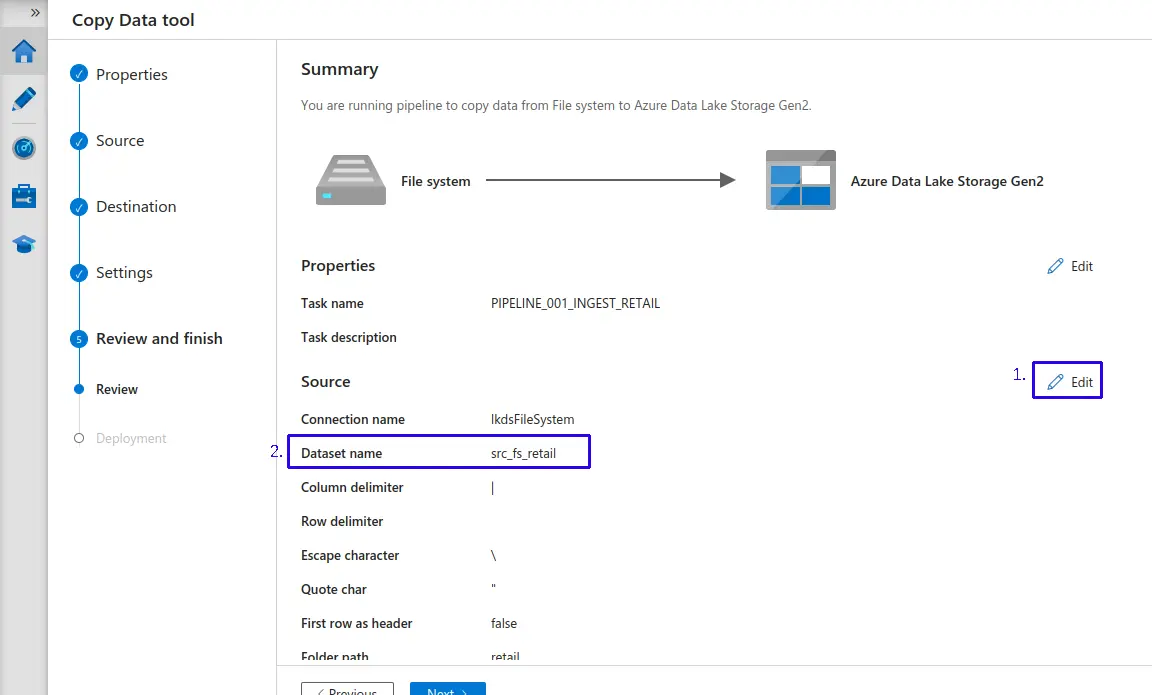
- 1.- Haz clic en "Edit"
- 2.- Asignale un nombre personalizado, por buenas practicas he decidido utilizar la siguiente convención llamando el origen como "
src_fs_retail". - Continuamos, desplazamos hacia abajo.
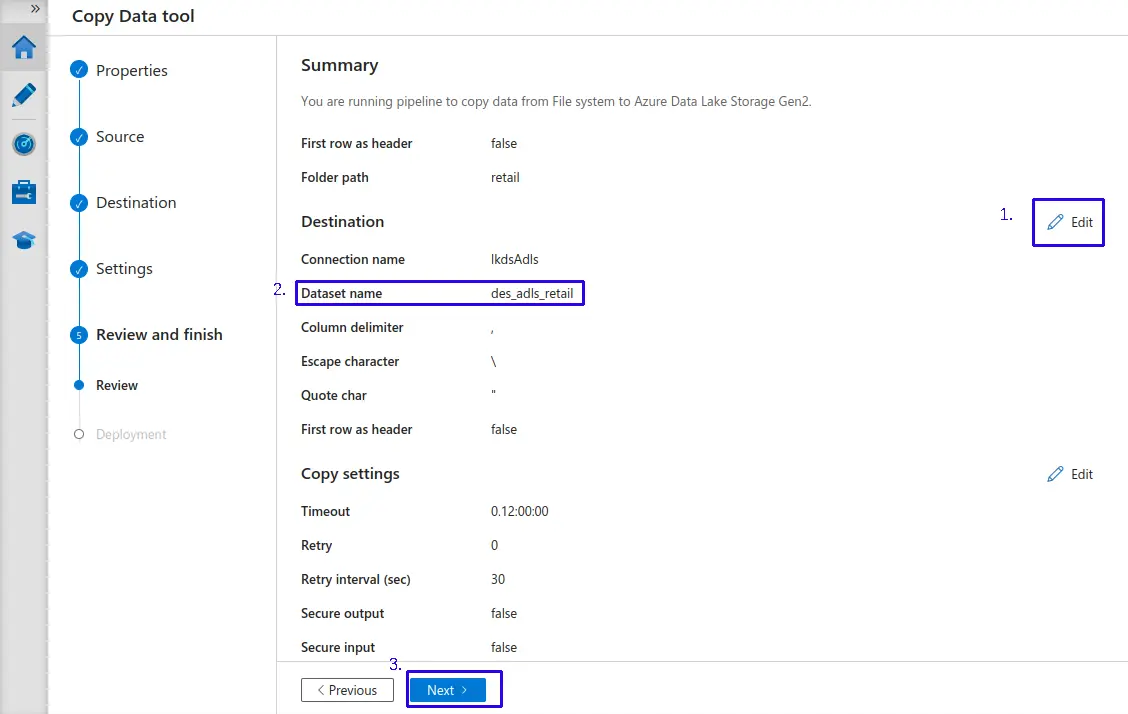
- 1.- Haz clic en "Edit"
- 2.- Asignale un nombre personalizado, por buenas practicas he decidido utilizar la siguiente convención llamando el destino como "
des_adls_retail". - Clic en el botón de "Next >"
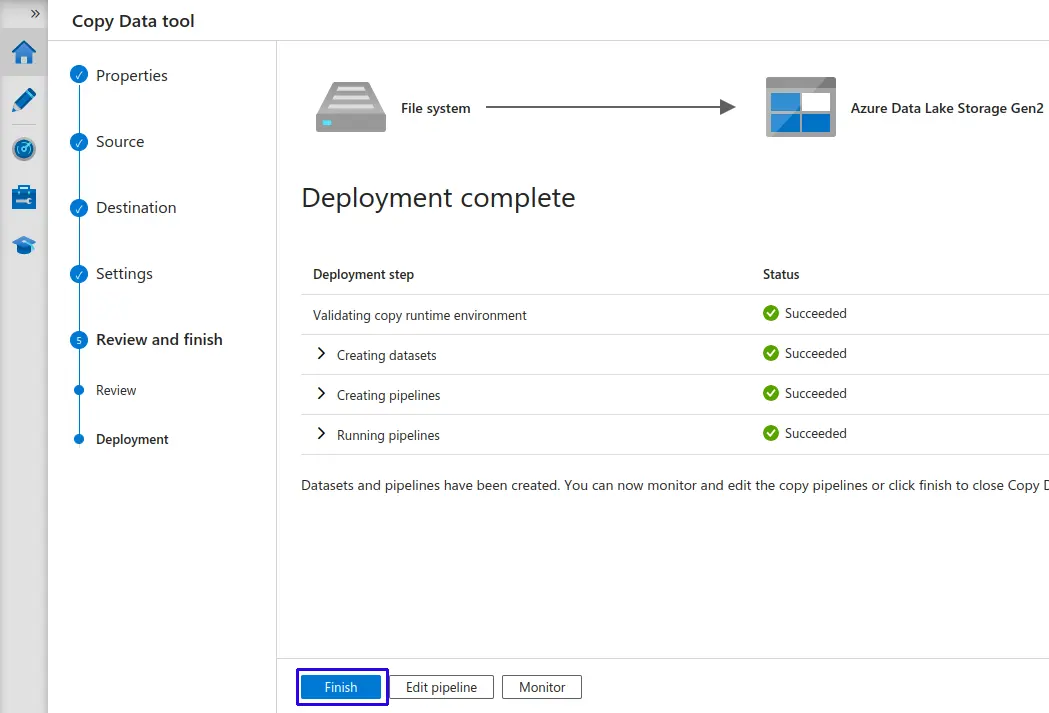
Validamos que el Deployment este completado y le damos clic al botón "Finish".
Regresamos a “Author”, seleccionamos nuestro pipeline "PIPELINE_001_INGEST_RETAIL" y ya lo podemos ejecutar con "Debug".
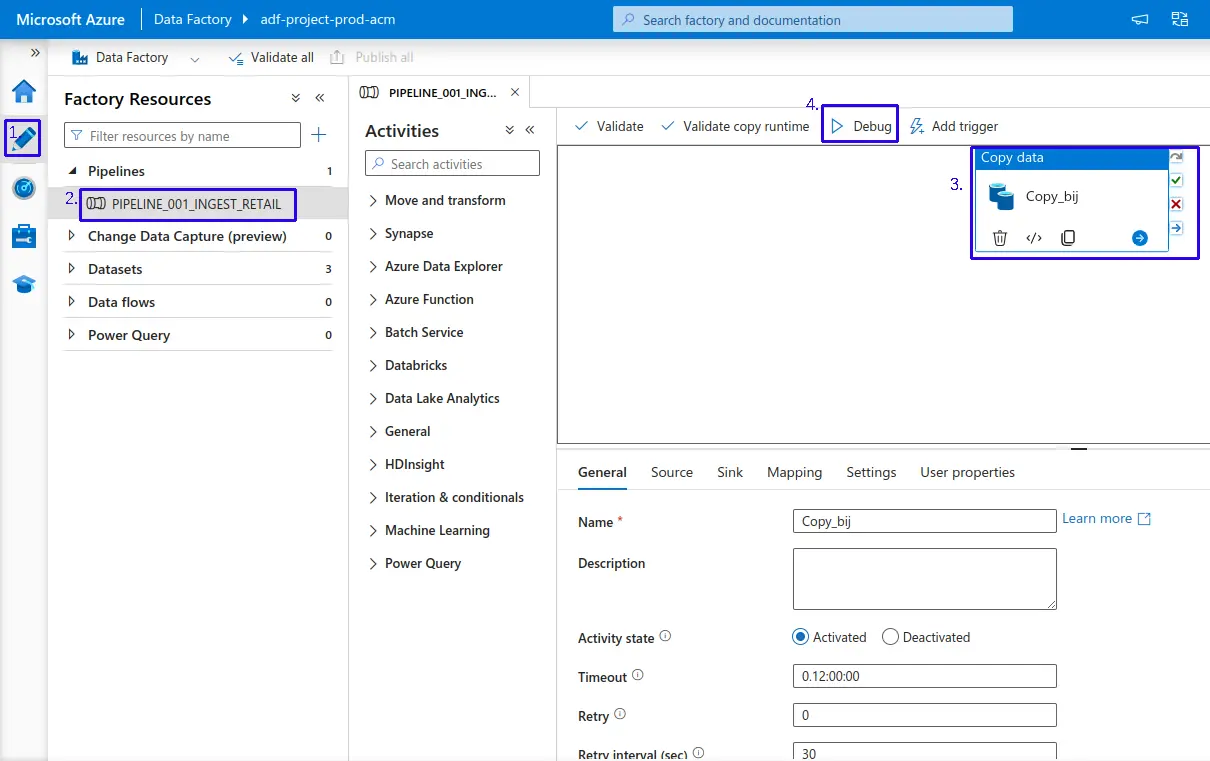
- En la parte inferior podremos validar si nuestro pipeline se ejecutó correctamente, además de tener datos adicionales sobre la ejecución.
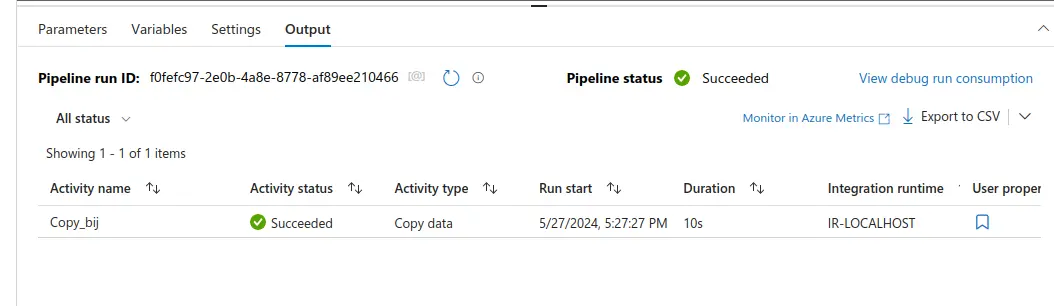
- Si deseas cambiar la extensión de los archivos en el destino, puedes ir al apartado "Sink" y en la opción "File extension" actualizar al formato requerido.
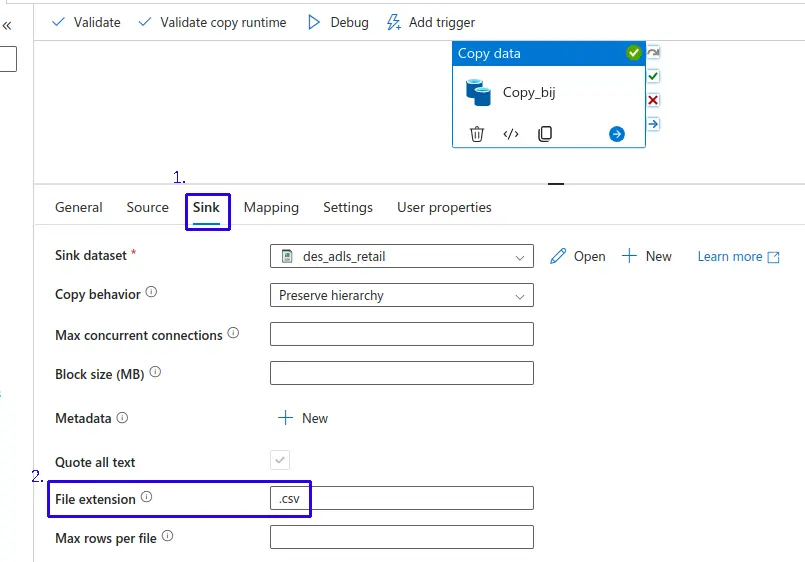
- Podemos realizar un "Publish all" para guardar todas las actualizaciones en nuestro pipeline
Finalmente podemos regresar a nuestro “ADLS”container “project” y validar la data.
Orquestación de Pipeline Master - Proyecto¶
Requiere tener creado el recurso de Azure Databricks con los Notebooks cargados.
También es necesario tener el pipeline creado previamente para la ingesta de datos desde el recurso de Virtual Machine hacia el recurso Azure Data Lake Storage Gen2, los cuales también deben estar creados previamente.
-
Iniciamos con la creación del Pipeline.
-
En Data Factory nos dirigimos a "Author" en la sección de "Pipelines" buscamos los 3 puntos (...) al colocar el puntero encima, seleccionamos y haz clic en "New pipeline".
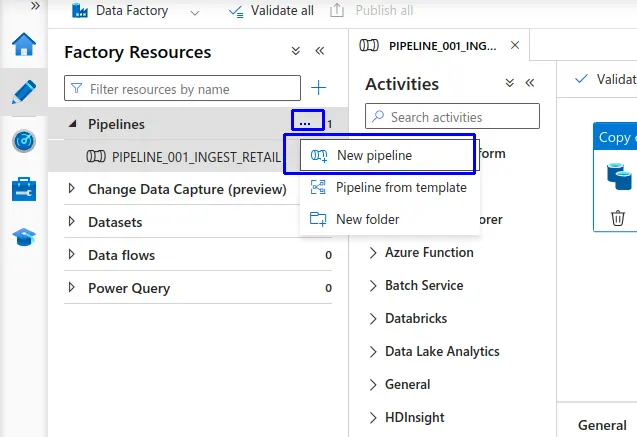
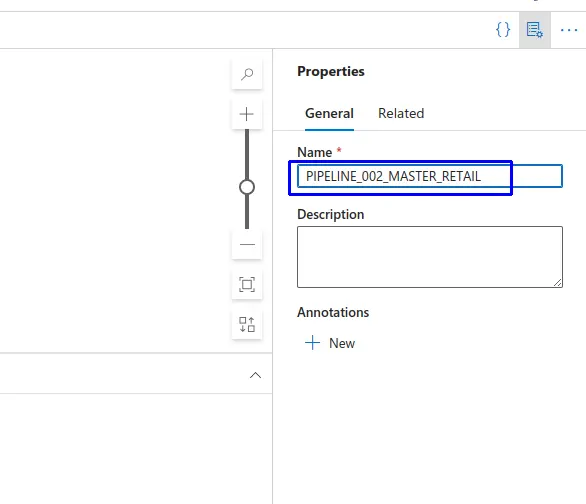
- Se nos apertura la interfaz de "Properties" donde le asignamos el nombre al Pipeline en este caso le pondremos como nombre "
PIPELINE_002_MASTER_RETAIL".
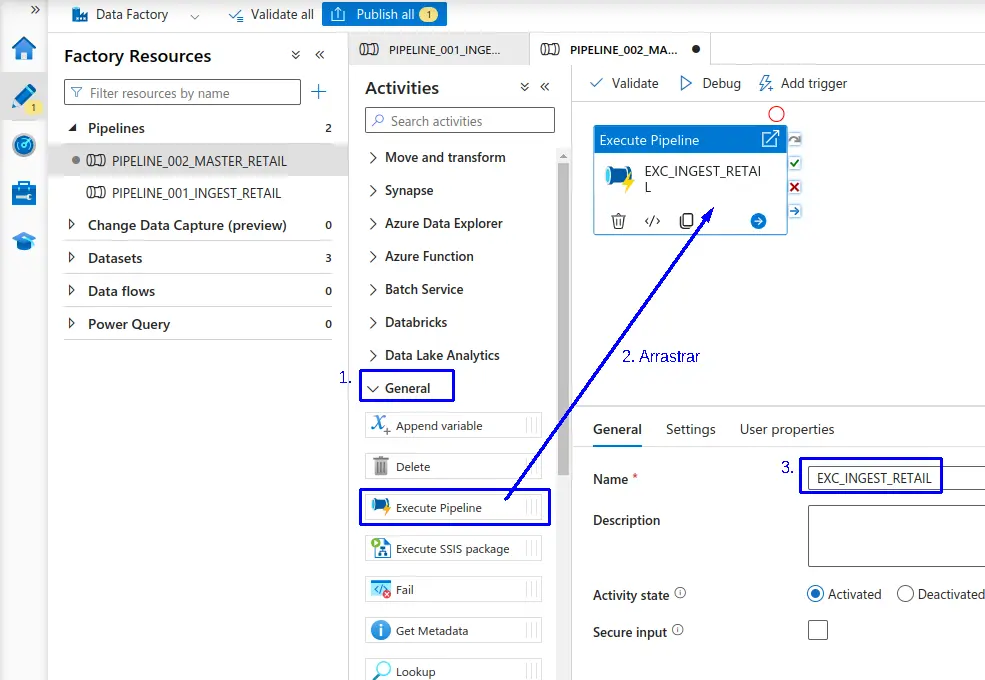
- Una vez creado el pipeline nos dirigimos al apartado de "Actividades" y en la sección de "General" arrastramos "Execute Pipeline" el cual utilizaremos para ejecutar el pipeline anteriormente creado.
- Establecemos el nombre para el "Execute Pipeline".
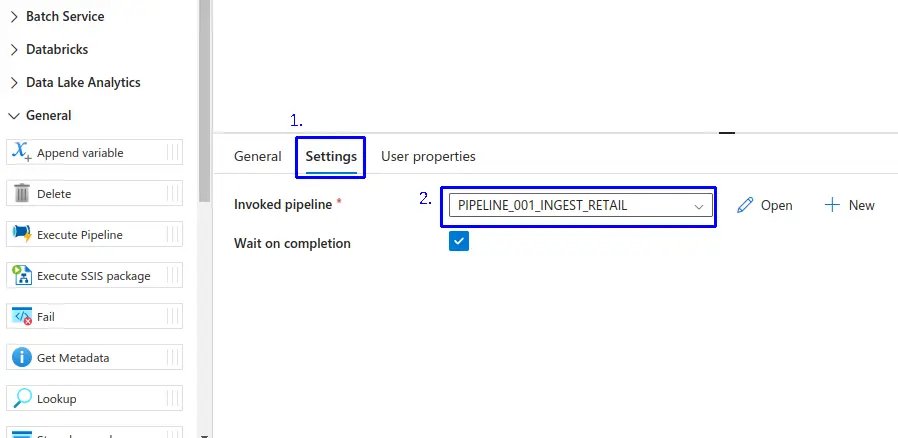
- 1.- Nos dirigimos a la pestaña de "Settings".
- 2.- Seleccionamos el Pipeline a ejecutar.
- En el apartado de "Actividades" y en la sección de "Databricks" arrastramos "Notebook" el cual utilizaremos para ejecutar un notebook en databricks.
- Establecemos el nombre para el "Notebook".
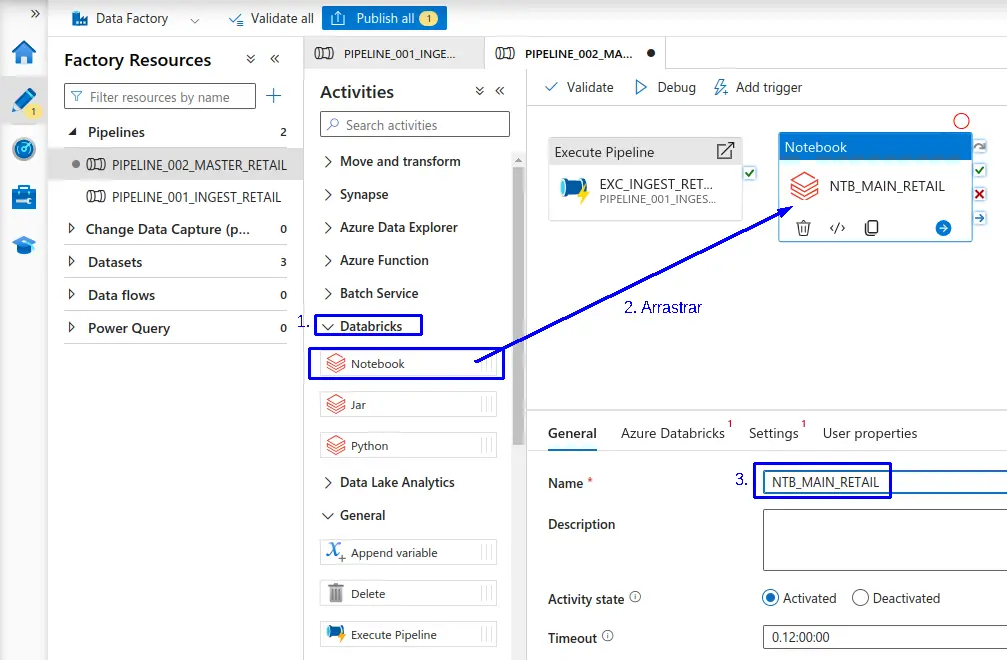
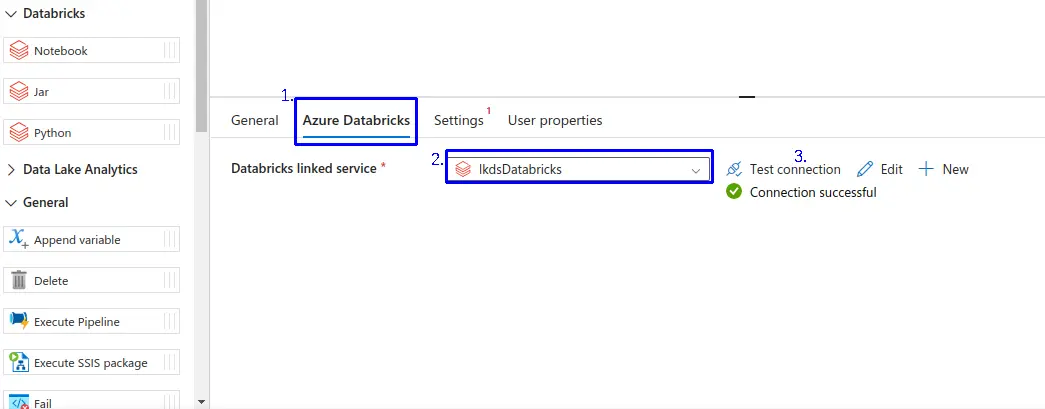
- 1.- Nos dirigimos a la pestaña de "Azure Databricks".
- 2.- Seleccionamos el linked services de Azure Databricks.
- 3.- Validamos la conexión haciendo clic en la opción "Test connection"
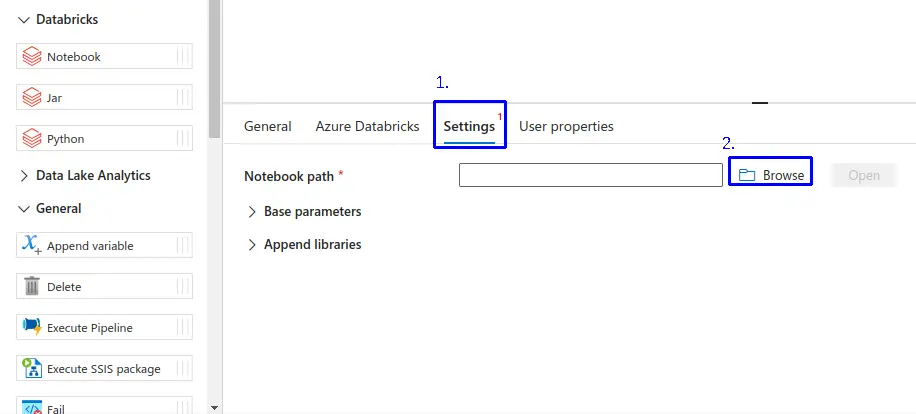
- 1.- Nos dirigimos a la pestaña de "Settings".
- 2.- Haz clic en "Browse", para buscar el notebook que se va a utilizar.
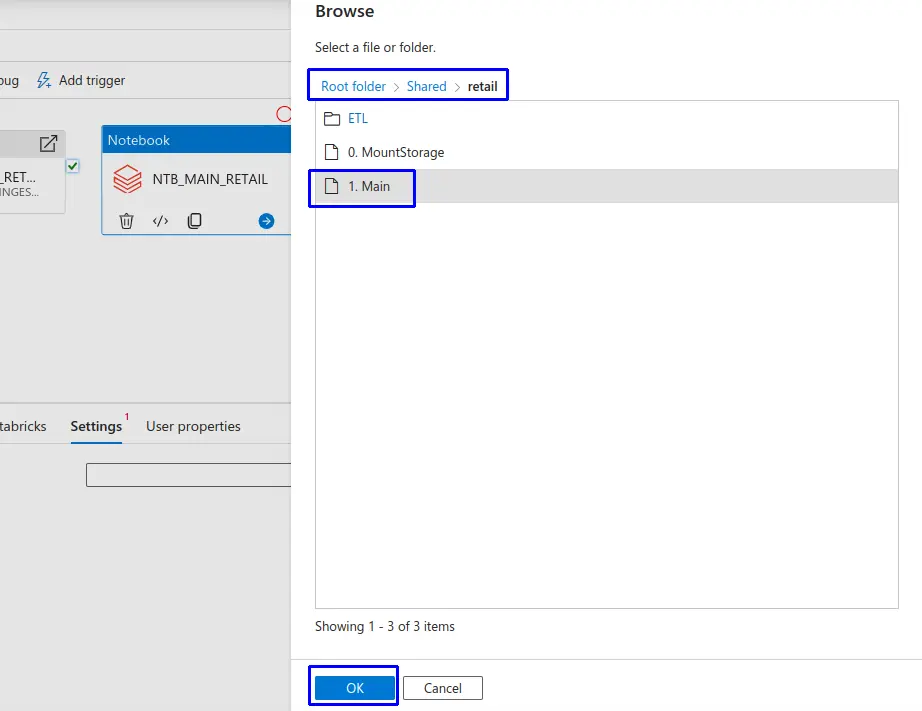
- En la interfaz de "Browse", buscamos el notebooks previamente cargado en el recurso de Azure Databricks.
- Clic en el botón "Ok".
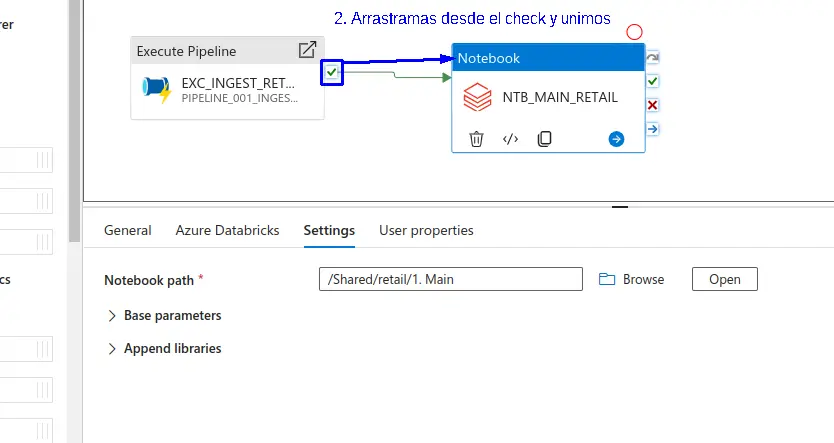
- Nos ubicamos en el check verde del "Execute Pipeline" y arrastramos en dirección al "Notebook", para lograr que se ejecute en un orde determinado.
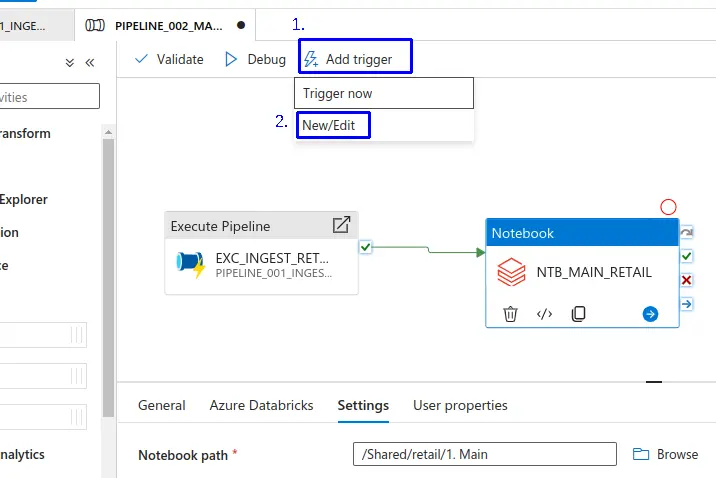
Crear Trigger¶
- 1.- Nos dirigimos a "+ Add Trigger".
- 2.- Haz clic en "New/Edit".
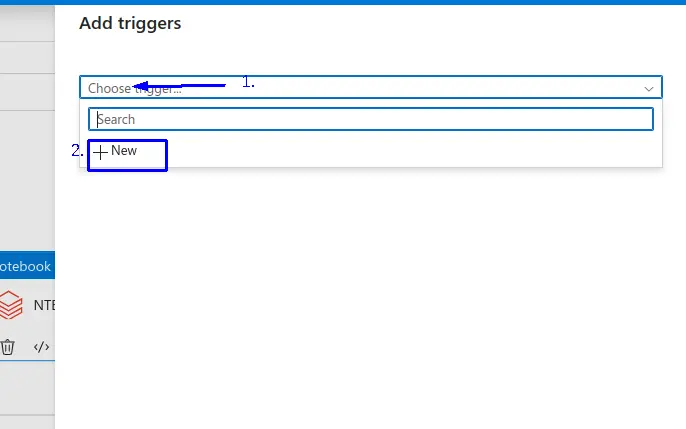
- 1.- Damos clic en "Chosse trigger".
- 2.- clic en "+ New".
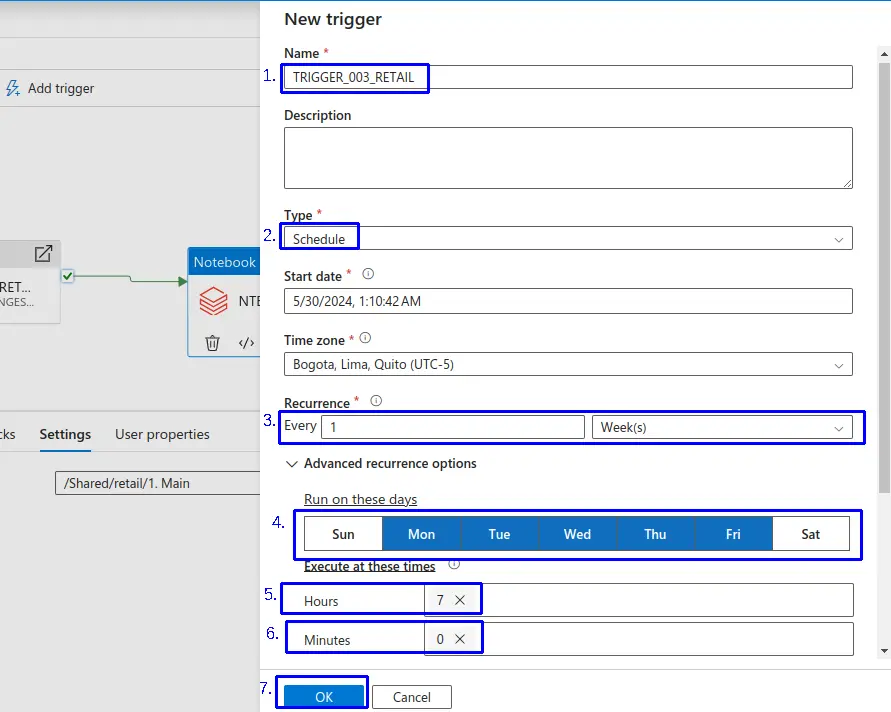
Se nos apertura la interfaz "New Trigger" donde completamos:
- 1.- Name: Asignamos un nombre a nuestro trigger en este caso le asignamos "
TRIGGER_003_RETAIL". - Podemos escribir una descripcion de nuestro trigger de ser requerido.
- 2.- Con respecto al Type: Seleccionamos el tipo "Schedule".
- Podemos establecer la Zona de tiempo.
- 3.- Podemos establecer la Recurrencia donde podemos establecer:
- 4.- Para "Weeks" seleccionamos los días de la semana.
- 5.- Establecemos la hora.
- 6.- Establecemos el minuto.
- 7.- Una vez configurado hacemos clic en el botón "Ok".
- Haz clic en el botón "Ok".
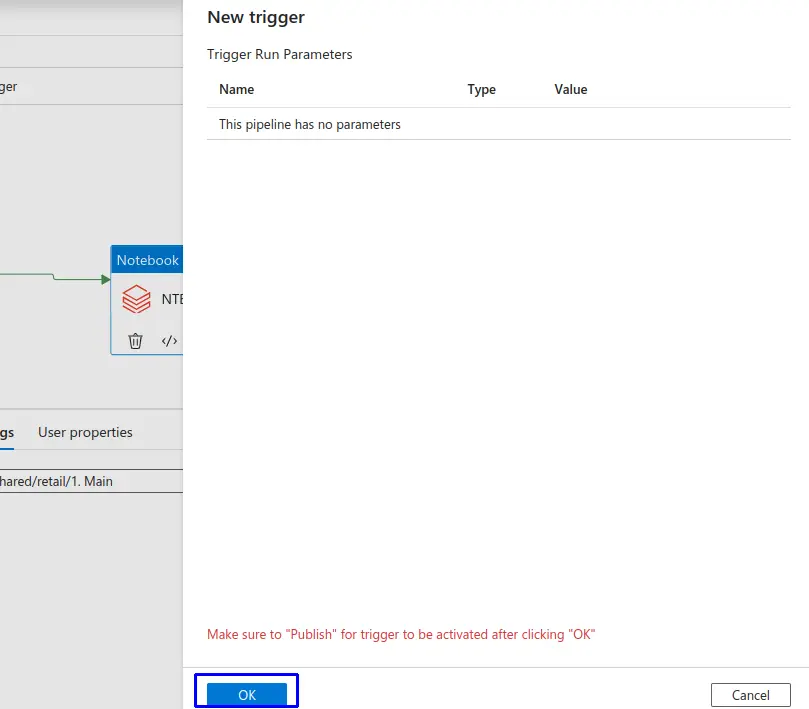
- Finalmente podemos observar y verificar el nuevo trigger creado.
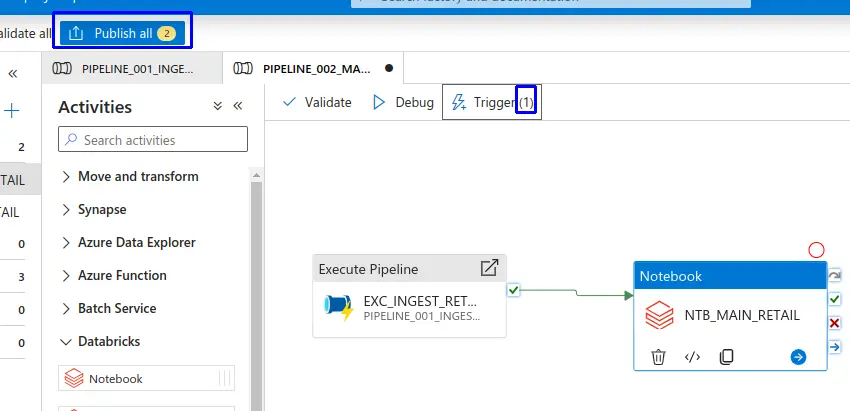
Organización de Pipelines con directorios¶
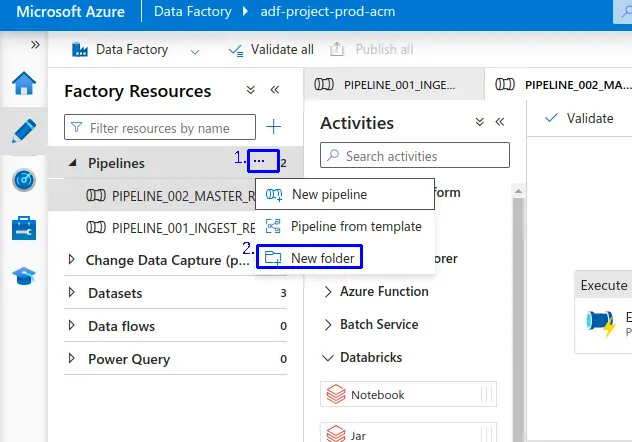
- En Data Factory nos dirigimos a "Author" en la sección de "Pipelines" buscamos los 3 puntos (...) al colocar el puntero encima, seleccionamos y haz clic en "New folder".
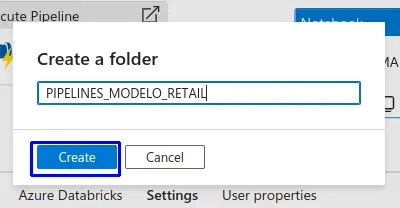
- En la siguiente interfaz asignamos un nombre a nuestro folder.
- Clic en "Create"
- Una vez creado el folder, podemos arrastrar los pipelines que se requiera segmentar por proyecto.
Además podemos crear un folder para los dataset y arrastrar los Dataset del proyecto.